Andrew and Erna Viterbi Faculty of Electrical and Computer Engineering, Technion - Israel Institute of Technology
Overview
Human subjective evaluation is optimal to assess speech quality for human perception, and the recently introduced deep noise suppression mean opinion score (DNSMOS) metric was shown to estimate human ratings with great accuracy [1]. Still, the signal-to-distortion ratio (SDR) metric is widely used to evaluate residual-echo suppression (RES) systems by estimating speech quality during double-talk [2]. However, since the SDR is affected by both speech distortion and residual-echo presence, it does not correlate well with human ratings according to the DNSMOS. To address that, we introduce two objective metrics to separately quantify the desired-speech maintained level (DSML) and residual-echo suppression level (RESL) during double-talk. These metrics are evaluated using a deep learning-based RES-system with a tunable design parameter [3] using 280 hours of real and simulated recordings [4]. We show that the DSML and RESL correlate well with the DNSMOS with high generalization to various setups. Also, we empirically investigate the relation between tuning the RES-system design parameter and the DSML-RESL tradeoff it creates and offer a practical design scheme for dynamic system requirements.
 |
|---|
| General acoustic echo cancellation scenario. The nonlinear components of the echo are modeled with a nonlinear system and the residual echo is suppressed by a dedicated system. |
Acoustic Echo Cancellation Setup
We follow the notations in the figure above and briefly cover the general acoustic echo cancellation setup for sake of benchmarking. Let
be the desired near-end speech signal and let
be the far-end speech signal. The near-end microphone signal
is given by
, where
represents additive environmental and system noises and
is a reverberant echo that is nonlinearly generated from
. Before applying RES, the nonlinear acoustic echo cancellation (NLAEC) system introduced in [5] is applied to reduce nonlinear echo. The NLAEC receives
as input and
as reference, and generates two signals: the echo estimate
, and the desired-speech estimate
, given by
The goal of the RES system is to suppress the residual echo
without distorting the desired-speech signal
.
DSML and RESL Measures
This section introduces the generation of the proposed evaluation measures. To derive the DSML and RESL, a deep learning-based RES system is considered as a time-varying gain. During double-talk, and the gain is given by
Before introducing the DSML and RESL metrics, the SDR and its drawbacks are examined. The SDR is defined as and is affected by both the desired-speech distortion and residual-echo presence. Thus, it makes no distinction between cases in which
comprises distortion-free speech and echo, or distorted speech without echo. Thus, the SDR does not correlate well with human ratings [1], since these scenarios clearly exhibit different human perception ratings and different DNSMOS values. A distinction between desired-speech distortion and residual-echo suppression is extremely valuable for evaluating RES during double-talk. Hence, we propose two objective metrics by applying
separately to the desired speech and noisy residual-echo estimate.
Formally, the DSML is calculated similarly to the SDR, but is applied only to the desired speech
such that
The RESL is derived by estimating the noisy residual-echo as , and evaluating the ratio
Note that the RES system may introduce a constant attenuation that leads to an artificial desired-speech distortion in the DSML. To ensure it is invariant to that attenuation, the DSML is compensated as in [6]. Explicitly, where
Code and demo
Code for generating the DSML and RESL measures can be found in my git repo.
The full paper accepted to WASPAA 2021 can be found in my ResearchGate page
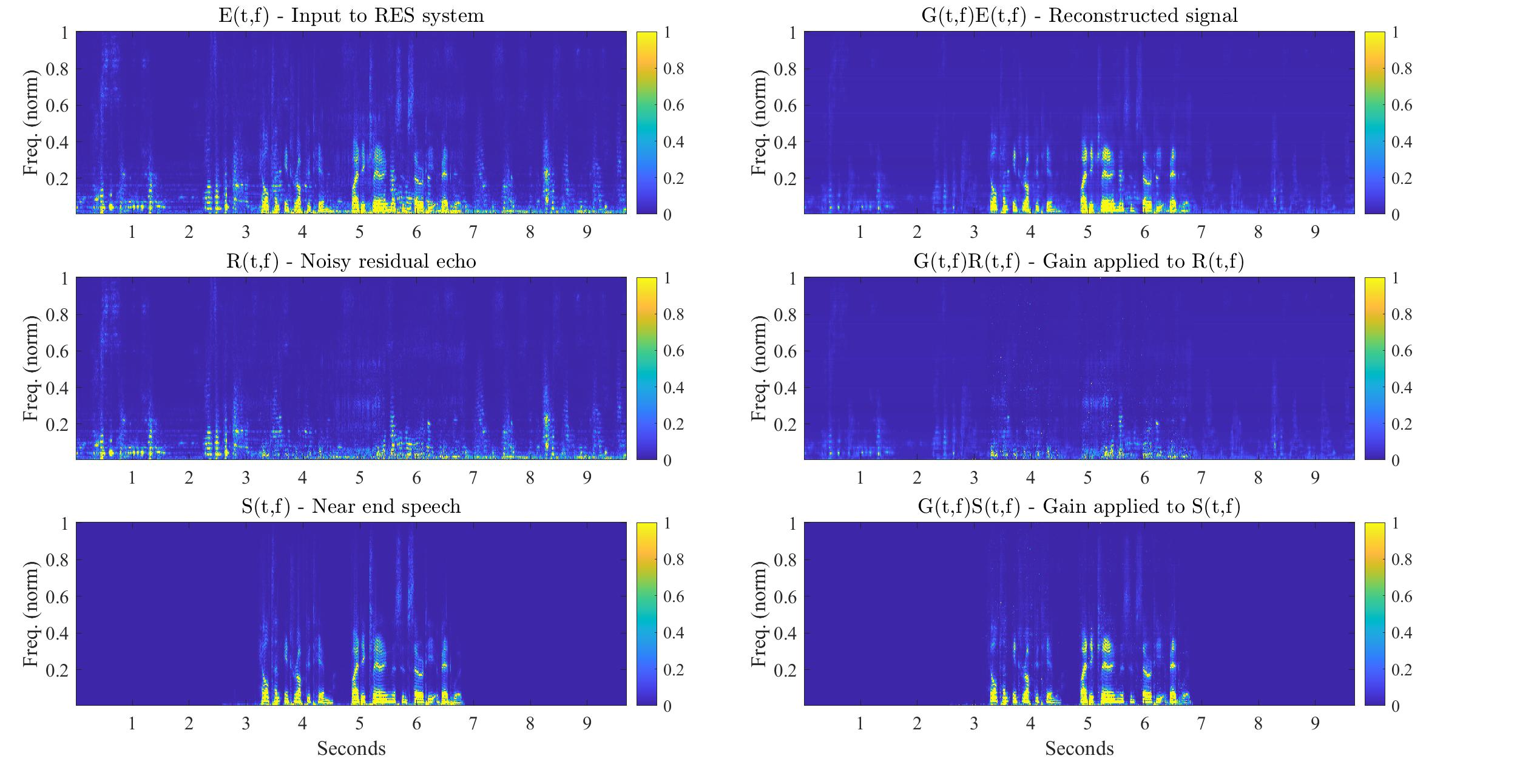
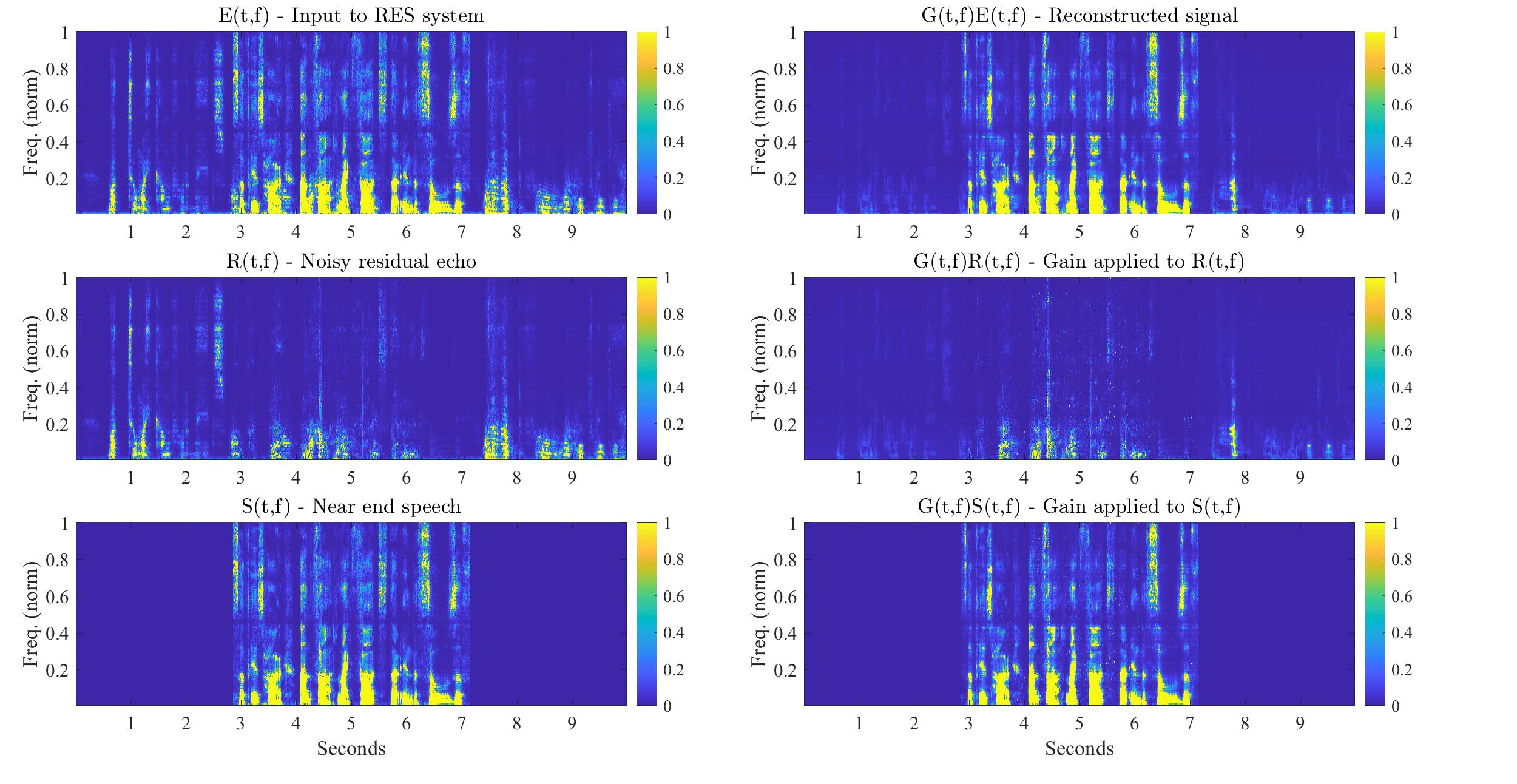
Demo examples can be found in my soundcloud playlist. These playlists include the separate effect of the RES system gain on the desired speech, namely , and on the noisy residual echo, namely
. It is also instructive to view the following comparison between applying the RES system gain on both the desired speech and the noisy residual echo, and applying it separately to each:
 |
|---|
 |
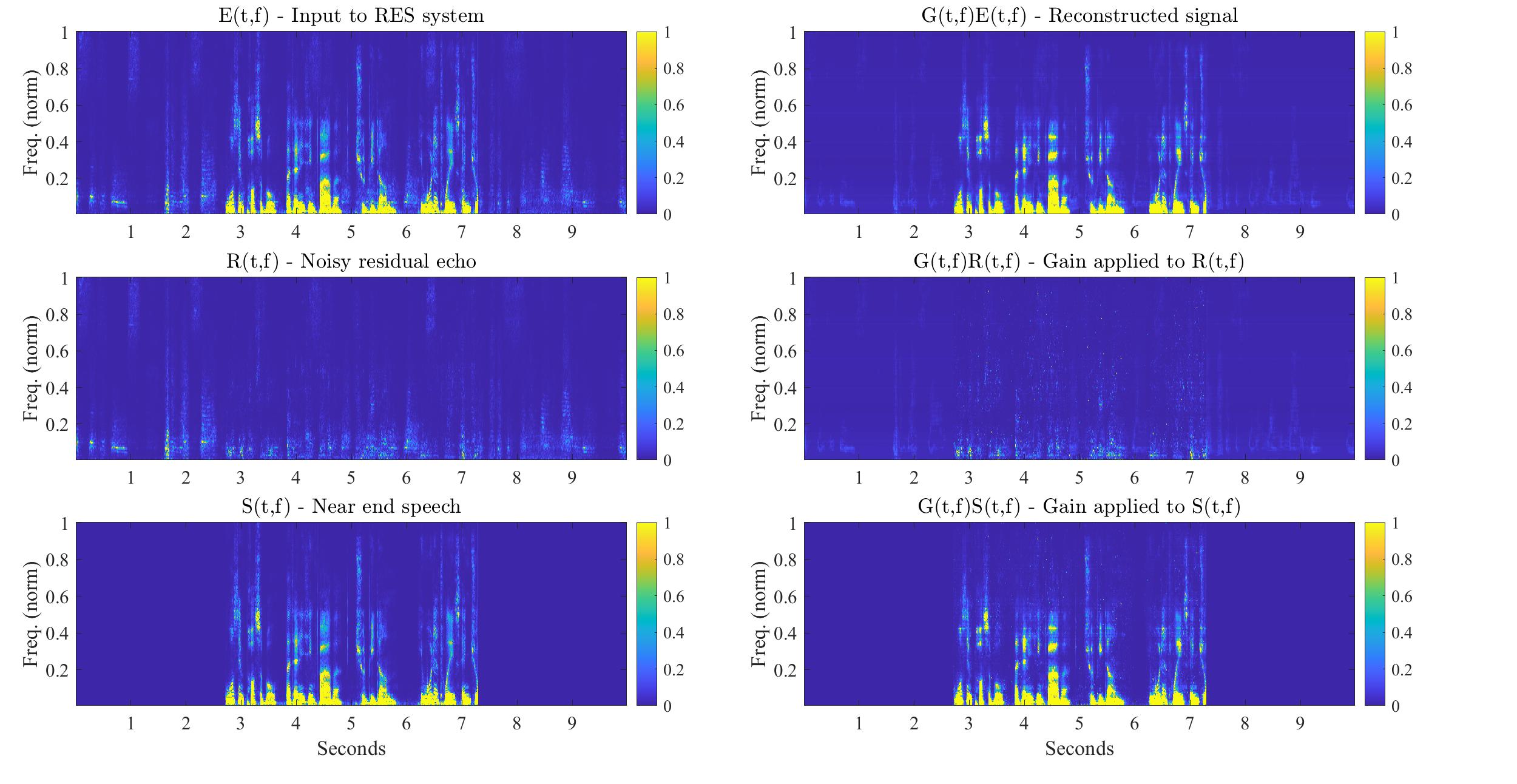 |
| The separate effect of the RES system gain on the desired speech and on the noisy residual echo in the short-time Fourier transform domain. |
Acknowledgements
This research was supported by the Pazy Research Foundation, the Israel Science Foundation (ISF), and the International Speech Communication Association (ISCA). We would also like to thank stem audio for their technical support.
References
[1] C. K. Reddy, V. Gopal, and R. Cutler, “DNSMOS: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors, ”arXiv:2010.15258, 2020.
[2] E. Vincent, R. Gribonval, and C. F ́evotte, “Performance measurement in blind audio source separation,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 14, no. 4, pp. 1462–1469, 2006.
[3] A. Ivry, I. Cohen, and B. Berdugo, “Deep residual echo suppression with a tunable tradeoff between signal distortion and echo suppression,” in Proc. ICASSP, June 2021.
[4] R. Cutler, A. Saabas, T. Parnamaa, M. Loida, S. Sootla, H. Gamper, et al., “Interspeech 2021 acoustic echo cancellation challenge,” in Proc. Interspeech, Sept. 2021.
[5] A. Ivry, I. Cohen, and B. Berdugo, “Nonlinear acoustic echo cancellation with deep learning,” in Proc. Interspeech. IEEE, Sept. 2021.
[6] G. Carbajal, R. Serizel, E. Vincent, and E. Humbert, “Multiple-input neural network-based residual echo suppression,” in Proc. ICASSP. IEEE, 2018, pp. 231–235.